Peter Naur first termed Data Science in the year 1974. But, the journey had begun in ancient times. Here’s a chronicle about the history of data science, tracing its path from the formative collection methods to the most advanced forms of data processing.
Data Science has taken the world by storm. It is not a single subject, but an all-encompassing term including programming, data mining, statistics, data visualization, analytics, and business intelligence.
Data Science is the complete process of collating huge data sets, managing them and deriving insights for several productive purposes. The field of Data Science is constantly evolving to keep pace with the changing technology and business practices.
Statistical data is the driving force behind the development of science, accounting, logistics, and other businesses. Data science as we know in the current times has a brief history. But, data collection at a massive scale and its analysis have existed since ancient times. Librarians, Scientists, statisticians, and demographers have discussed and worked with huge datasets for years.
Today, data analysis and extracting insights from it has emerged as the most coveted and intriguing task. It has even led to a new professional role in the form of a Data Scientist. Famous for his work in Big Data, American journalist, Kenneth Cukier, said, data scientists “combine the skills of software programmer, statistician, and storyteller/artist to extract the nuggets of gold hidden under mountains of data”.32
In this article, we recollect the history of data science with its many landmark events.
1663: John Graunt’s Extensive Demographic Data Collection
In 1663, John Graunt, a British demographer, recorded and analyzed every piece of information about mortality rates in London.1 Graunt’s objective was to build an effective warning system for the bubonic plague epidemic. John used the Rule of Three and used ratios by comparing years in the Bills of Mortality to estimate the population size of London and England, the birth and mortality rates of males and females, and the rise and spread of particular diseases. Graunt is also known as the ‘Father of Demographics.’2

During his first attempt at statistical data analysis, Graunt noted all his observations and findings in the book Natural and Political Observations Made upon the Bills of Mortality. This book was compiled based on data collected by John Graunt and offers a detailed account of the causes of death in the 17th century.
1763: Bayes Theorem
Published posthumously in 1763, Thomas Bayes’ theorem of conditional probability is one of the cornerstones of Data Science.3 This conditional probability is known as a hypothesis. This hypothesis is calculated through previous evidence or knowledge. Bayes’ theorem aims to revise existing predictions or theories (update probabilities) and offers additional evidence. This conditional probability is the possibility of an event if some other event has already happened.
1840: Ada Lovelace: The First Computer Programmer
Programming is critical to Data Science, and the person who pioneered it in the 17th century was Ada Lovelace, an English noblewoman. Ada Lovelace was an associate of Charles Babbage, the “father of computers.” Lovelace worked with Babbage on the “Difference Engine,” a mechanical calculator.4
In 1840, Ada Lovelace was working on a translation project for a paper written by an Italian engineer, Luigi Manabrea. The article was from the book: “Sketch of the Analytical Engine Invented by Charles Babbage, Esq” published in French. However, she went far beyond translating it. She included extensive notes in the paper, including a few of her theories and her analysis of the extensive ones.

In August 1843, the translated work was published in Taylor’s Scientific Memoirs and its final appendix, Note G, became extremely famous. In the paper, Lovelace proposed an algorithm for the engine for computing Bernoulli’s numbers. These are a complex series of rational numbers frequently used in arithmetic and computation.
This is the first instance of computer programming, which happened even before people thought the modern computer would ever be invented. Ursula Martin, an Ada Lovelace biographer and professor of computer science at the University of Oxford, said, “She’s written a program to calculate some rather complicated numbers — Bernoulli numbers… This shows off what complicated things the computer could have done.”5
Though Ada Lovelace’s algorithm is not directly related to Data Science, she was the first to lay the foundation of programming. Without this significant leap, Data Science would have been impossible to imagine.
1855: Florence Nightingale, the Victorian Medical Reformer, Used Data Visualization
Florence Nightingale was a Victorian Icon also known as a founder of modern nursing. She was known as the pioneer of using statistics and data visualization to analyze the spread of infectious diseases.6
Today, we can put up a fight against a pandemic thanks to the practical information systems set up by countries across the world. But in the 17th century, such a system was unheard of. According to statistics historian Eileen Magnello of University College London, Nightingale’s diagram, Rose is a variation of a pie chart or a polar area chart. Through the diagram, she showed that poor sanitation, and not battle wounds, were responsible for the death of the English soldiers during the Crimean War in the 1850s. She also stated that such deaths were avoidable. Nightingale used data that she and her staff collected during her duty in the camps and hospital.
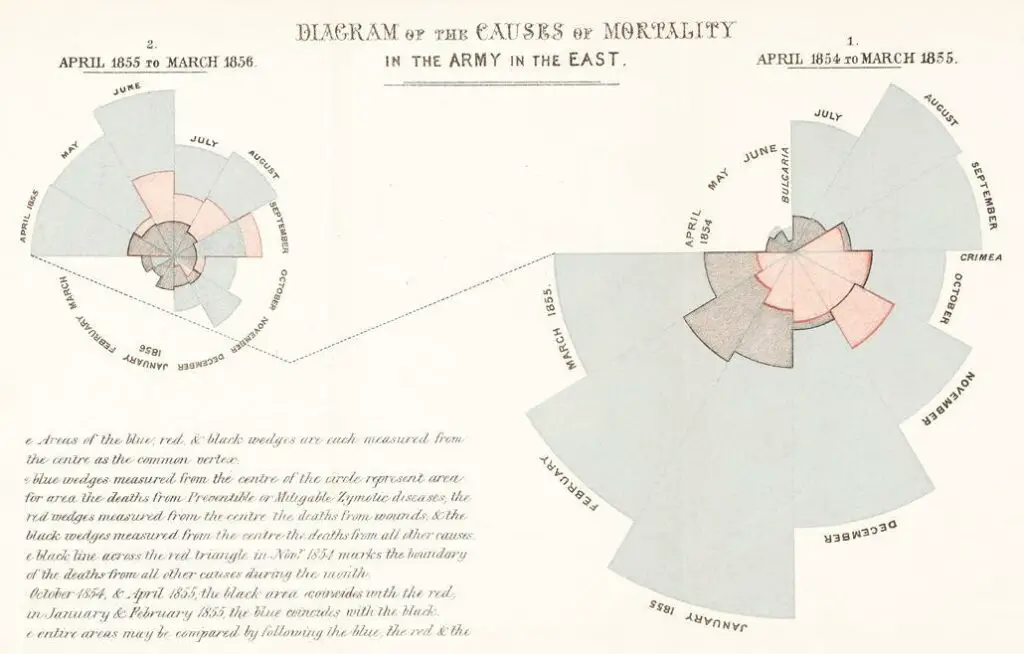
Nightingale also made a series of other charts to convince the authorities about the importance of sanitation. Visualizations were one of Nightingale’s preferred ways of communicating. She said, “Whenever I am infuriated, I revenge myself with a new diagram.”
Eventually, Nightingale’s ideas started getting acknowledged, and the sanitation needs for the Patients at military and civilian hospitals were taken care of.
1865: The Term Business Intelligence Is Coined
In 1865, Richard Miller Devens, an American historian, and author, first used the phrase “Business Intelligence” (BI) in his work, Cyclopædia of Commercial and Business Anecdotes. Today, we know business intelligence as analyzing data and creating actionable information to solve several business problems.78
Devans used it to describe how Sir Henry Furnese, an English banker, earned massive profits from information by gathering data from various sources and acting on it to outdo his competitors.
He stated, “Throughout Holland, Flanders, France, and Germany, he maintained a complete and perfect train of business intelligence. The news of the many battles fought was thus received first by him, and the fall of Namur added to his profits, owing to his early receipt of the news.”
1884: Hollerith Marks the Beginning of Data Processing
In 1884, Herman Hollerith, an American inventor, and statistician invented the punch card tabulating machine, which marked the beginning of data processing. Hollerith is also known as the Father of Modern Automatic Computing.9
This tabulating device that Hollerith developed was later used to process the 1890 US Census data. Later, in 1911, he founded the Computing-Tabulating-Recording Company, which became International Business Machine or IBM.

1936: Alan Turing Introduced ‘Computable Numbers’
In 1936, Alan Turing’s paper, On Computable Numbers, introduced Universal Machine performing complex computations like our modern-day computers.10 The paper propagated the mathematical description of a hypothetical computing device that could mimic the ability of the human mind to manipulate symbols. It won’t be wrong to say that Turing has pioneered modern-day computing through his path-breaking concepts.

According to Turing, “computable numbers” are the ones that a definite rule can define and calculated on the universal machine.11 He also stated that these computable numbers “would include every number that could be arrived at through arithmetical operations, finding roots of equations, and using mathematical functions like sines and logarithms—every number that could arise in computational mathematics.”
1937: IBM Gets Social Security Contract
Franklin D. Roosevelt’s administration in the USA commissioned the first significant data project in 1937. This happened after the Social Security Act became law in 1935.12 The government had undertaken a massive bookkeeping project to track payroll contributions from 26 million Americans and over 3 million employers. Ultimately, IBM received the contract to develop a punch card-reading machine for this project called IBM Type 77 collators.13

These collators could work with two sets of punch cards, compare them and then merge them into a single pile. The machine was efficient enough to handle nearly 480 cards per minute.
Collators emerged as the fastest way of combining data sets or identifying duplicate cards. So strong was the impact of the device that the 80-column punch cards that those IBM Type 77 collators used became an industry standard for the next 45 years.
1943: The First Data Processing Machines
In 1943, Tommy Flowers, the Post Office electronics engineer from the UK, designed a theoretical computer, Colossus.14 It was one of the first data processing machines to interpret Nazi codes during WWII. The Colossus could perform Boolean operations as well as computations to analyze humongous data sets.15
This revolutionary device looked for patterns in intercepted messages at a rate of 5,000 characters per second, reducing the execution time from weeks to just a few hours.
Tommy Flowers made a significant breakthrough by proposing that wheel patterns can be generated electronically in ring circuits. This employed removing one paper tape and completely doing away with the synchronization problem.
1962: John Tukey Projected the Impact of Electronic Computing on Data Analysis
In 1962 John W. Tukey projected the impact of present-day electronic computing on data analysis.16 Tukey was a chemist-turned statistician who contributed mainly to statistics during the 1900s. He also pioneered a significant research project to study various graphical methods for data analysis. The invention of Box-and-Whisker Plot, the Stem-and-Leaf Diagram, and Tukey’s Paired Comparisons are three of Tukey’s most prized contributions to statistics.
John W. Tukey also authored “The Future of Data Analysis” in 1962, which was the first time in history that data science was globally recognized. Interestingly, Tukey introduced the term “bit” as a contraction of “binary digit.” In the book “Annals of the History of Computers” Tukey is credited as the person behind the word “bit,” a contraction of “binary digit,” the term describing the 1s and 0s that are the basis of computer programs.
1974: Peter Naur Analyzes Contemporary Data Processing
In 1974, Peter Naur defined the term “data science” as “The science of dealing with data, once they have been established, while the relation of the data to what they represent is delegated to other fields and sciences.”17 He published the book Concise Survey of Computer Methods in Sweden and the United States, analyzing contemporary data processing methods across many applications. The mention of Data Science in the book revolves around data as defined in the course plan called Datalogy presented at the IFIP Congress in 1968. The definition of data is “a representation of facts or ideas in a formalized manner capable of being communicated or manipulated by some process.”
1977: The International Association for Statistical Computing Was Established
In 1977, The International Association for Statistical Computing (IASC) was established as a Section of the ISI during its 41st session.18 The premier statistical body stated: “It is the mission of the IASC to link traditional statistical methodology, modern computer technology, and the knowledge of domain experts to convert data into information and knowledge.” The objectives of the Association are to promote a global interest in practical statistical computing and exchange technical knowledge through various international networking events between statisticians, computing professionals, corporations, government, and the general public.
1977: Exploratory Data Analysis by Tukey
Exploratory data analysis is a branch that analyzes data sets to summarize their primary characteristics, using methods like data visualization and statistical graphics.19 In 1977, John W. Tukey wrote the book Exploratory Data Analysis where he argued that statistics placed undue importance on statistical hypothesis testing (confirmatory data analysis). The objective behind this approach was to examine the data before applying a specific probability model. Tukey also mentioned that intermingling the two types of analyses and using them on the same data set might result in systematic bias. This is primarily due to the inherent hypothesis testing suggested by a given dataset.
1989: The Emergence of Data Mining
In 1989, Gregory Piatetsky-Shapiro organized and chaired the first Knowledge Discovery in Databases (KDD) workshop.20 The term “Knowledge Discovery in Databases” (KDD) was coined by Gregory Piatetsky-Shapiro. In the 1990s, The term “data mining” first appeared in the same database community.
Today, almost every industry leverages data mining to analyze data and identify trends to achieve business objectives such as customer base expansion, pricing prediction, fluctuations in stock prices, and customer demand.
1996: The Term ‘Data Science’ Used for the First Time
For the first time in 1996, the term “data science” was included in the title of the fifth conference of the International Federation of Classification Societies (IFCS) in Kobe, Japan. The meeting was called “Data science, classification, and related methods.”(21)
The papers presented during the conference were related to the field of data science, including theoretical and methodological advances in domains about data gathering, classification, and clustering. The knowledge-sharing sessions also revolved around exploratory and multivariate data analysis.
1997: Jeff Wu Insists Statistics be Renamed As Data Science
In 1997, Jeff Wu, during his inaugural lecture titled “Statistics = Data Science?” as the H. C. Carver, Chair in Statistics at the University of Michigan, suggested that statistics be renamed “data science” and statisticians be called “data scientists.”22 He characterized statistics as a combination of three elements, data collection, data modeling and analysis, and decision making.
Wu, a Taiwanese mathematician, and statistician explained that a new name would help statistics have a distinct identity and avoid confusion with other streams like accounting or data collection.
1997: The term ‘Big Data’ Was Coined
In 1997, researchers from NASA, Michael Cox and David Ellsworth, first used the word, ‘Big Data’ in their paper, “Application-controlled demand paging for out-of-core visualization.”30.

Big Data refers to enormous data sets that usual software tools and computing systems cannot handle. In April 1998, John R. Mashey, an American computer scientist and entrepreneur, used the term Big Data in his paper Big Data … and the Next Wave of InfraStress.31
2001-2005: Data Science Gains Prominence
Credit goes to William S. Cleveland for establishing data science as an independent discipline. In a 2001 paper, he called for an expansion of statistics beyond theory into technical areas.23 After early 2000, the term “Data science” became more widely used in the next few years: In 2002, the Committee on Data for Science and Technology launched the Data Science Journal. In 2003, Columbia University launched The Journal of Data Science.24
In 2005, the National Science Board called for a distinct career path for data science to ensure experts handle digital data collection.25 The National Science Board published “Long-lived Digital Data Collections: Enabling Research and Education in the 21st Century” as support to promote Data Scientists.
2006: Hadoop 0.1.0 Was Released
2006 saw the launch of Hadoop 0.1.0, an open-source, non-relational database. Hadoop was based on another open-source database, Apache Nutch.26 Yahoo deployed Hadoop using the programming model of MapReduce to process and store massive application volumes of several databases.

The launch of Hadoop also marked the beginning of Big Data. Doug Cutting and Mike Cafarella began working on Hadoop in 2002 when both were a part of the Apache Nutch project. The core objective behind the Nutch project was handling billions of searches and indexing millions of web pages. In July 2008, Apache successfully examined a 4000 node cluster with Hadoop.
Finally, Apache Hadoop was publicly released in November 2012 by Apache Software Foundation. Hadoop works by splitting files into large blocks and distributing them across nodes in a cluster. After this, it transfers the packaged code into several nodes allowing parallel data processing. This enabled faster and efficient processing of the dataset.
2007: The Research Center for Dataology and Data Science Was Established
In 2007, The Research Center for Dataology and Data Science was set up at Fudan University, Shanghai, China.27 In 2009, Yangyong Zhu and Yun Xiong, two of the researchers of the university, published “Introduction to Dataology and Data Science,” where they stated that Dataology and Data Science is a new science and independent research field, and different from natural science and takes data in cyberspace as its research object. 28
On June 22-23, 2010, Research Center for Dataology and DataScience, Fudan University, China, hosted “The First International Workshop on Dataology and Data Science.” It saw participation from over 30 scholars from international and domestic campuses exchanging ideas on “Dataology and Data Science.”
2014: AMSAT Changes Name to Section on Statistical Learning and Data Science
In 2014, the American Statistical Association’s Section on Statistical Learning and Data Mining changed its name to the Section on Statistical Learning and Data Science, clearly reflecting the popularity of data science.29 The section name change might seem like a small step, but it signifies that the ASA has taken a significant step to strengthen the connection between statistics and data science.
Walking Forward
Data Science has evolved immensely over the past decade and has conquered every industry that depends on data. There is also a massive demand for data scientists from varied academic and professional backgrounds.
Data stockpiles have seen an exponential increase, thanks to advances in storage and processing and storage which are cost-effective and efficient. According to IDC, by 2025, there will be over 175 zettabytes of data globally.
In earlier days, data wasn’t as accessible as in the present times. Also, people were too skeptical about sharing their information. Even today, privacy and ethics are the foundation of data collection. Therefore every data scientist needs to operate within an ethical framework as the volume of data expands.
Experts believe that automation, blockchain, analytics, and democratization will shape the future of data science as a core function of business management.
Sources: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32