Look-ahead bias occurs by using information not available or known in the analysis period for a study or simulation, leading to inaccurate results.
An often-overlooked point regarding look-ahead bias is that it isn’t just about when a data observation becomes available; it’s also about when you can access the data.
One of the challenges with look-ahead bias is that it is difficult to detect during backtesting. The backtest cannot signal that the data is biased. Often our only indication that the data contains bias is that the returns are excellent. The best solution to prevent backtesting is to thoroughly understand look-ahead bias and then set up systems and processes to protect against it. Let’s look at a few examples of look-ahead bias and then how to prevent it.
Look-Ahead Bias Examples
In the below examples, think about how each instance introduces look-ahead bias. Try to identify the following three moments in time for each piece of data:
- When was the data observed?
- At what time was the data released?
- What time was it available to us?
Selection Look-Ahead Bias
Consider you’re a fan of Apple products, and you know the company has been performing well over recent history. You decide to create a trading strategy to trade Apple, backtesting your approach over the 2014-2019 period. This strategy’s performance will look unreasonably good as Apple’s stock price increased by 190% compared to 63% over the same five-year period for the S&P 500 index.
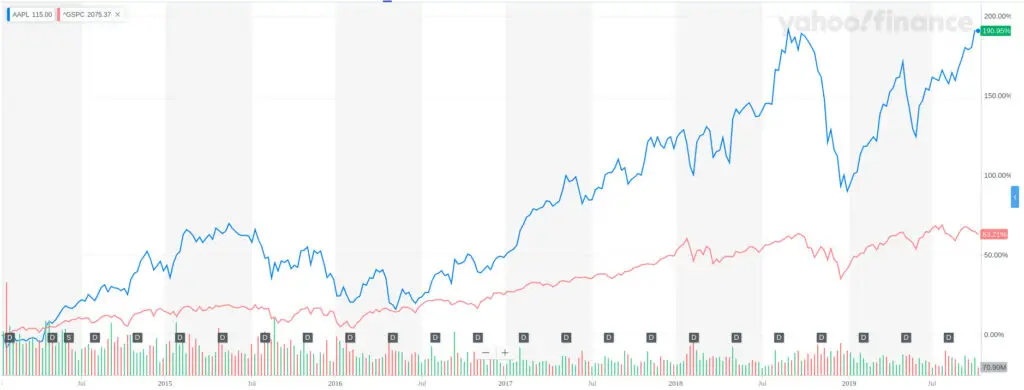
| Moment | Date |
|---|---|
| Data Observation | Last five years ending on 10/8/2019 |
| Data Released | 10/9/2019 |
| Data Available | 10/9/2019 |
Data Observations & Revisions
Let’s examine a more complicated example incorporating look-ahead bias using Federal Reserve Economic Data. The Bureau of Labor Statistics (BLS) released state and local employment data on March 13, 2017. The BLS initially estimated that St. Louis added 38,300 jobs in 2016, but the revised data show that only 17,100 jobs were added. A trader using unemployment data in their strategy would need to simulate using the initial estimate until a revision was made available. Don’t be surprised employment data get revised.
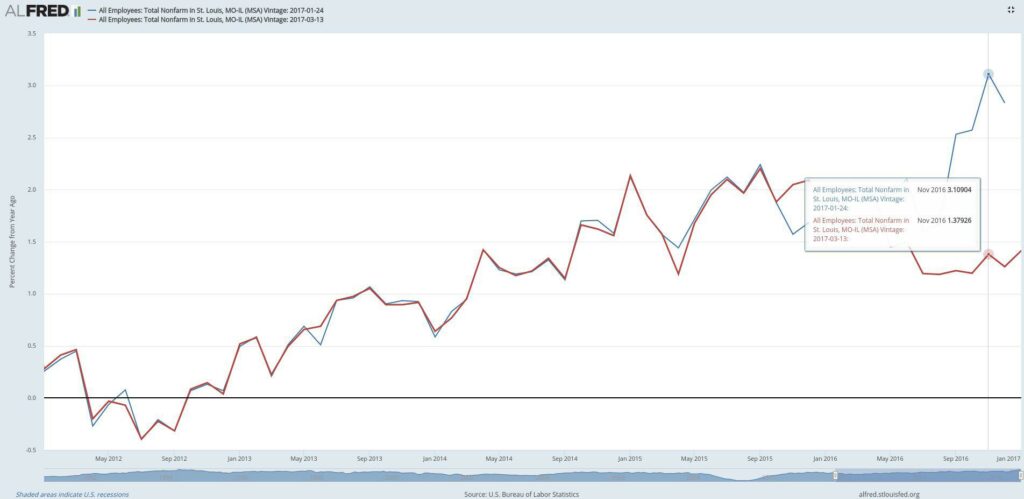
Let’s look at the moments in time for the first revised observation. The data is released at 8:30 AM, so our strategy should be able to trade on the data the same day it is released. If it’s hard to see from the chart, I’ve provided a table of the unemployment data.
| Moment | Date |
|---|---|
| Data Observation | 3/1/2012 |
| Data Released | 1/24/2017 |
| Data Revised | 3/13/2017 |
| Data Available | 3/13/2017 |
Release vs. Availability
Take a look at Apple’s income statement below. Imagine that we created a trading strategy that buys companies when their after-tax profit margin reaches 22%. In our example, Apple reaches this level of profitability on 9/30/2018, so we buy, right?
$59,531,000 / $265,595,000 = 22.4%
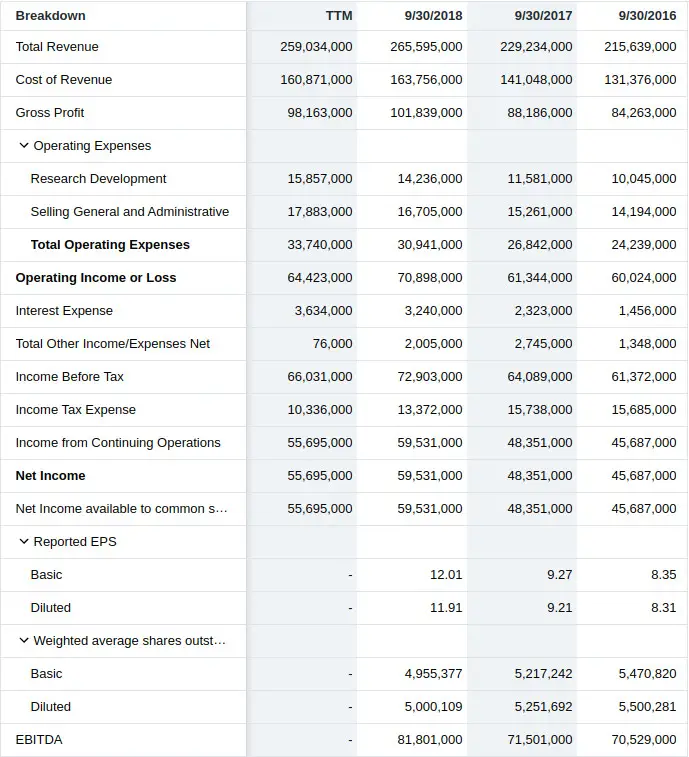
Unfortunately, the earnings observation for the quarter ended 9/29/2018 wouldn’t be available until the data was released to the public after market close. An after-hours release means we could only start trading using the information the next day when the market opens.
| Moment | Date |
|---|---|
| Data Observation | 9/30/2018 |
| Data Released | 11/1/2018 |
| Data Available | 11/2/2018 |
How to Protect Against Look-Ahead Bias
To prevent look-ahead bias, you have to avoid it in your data and the backtesting system.
Bitemporal Data
The best way to protect against look-ahead bias at the data level is to use bitemporal modeling, or more simply, to record data along with two different timelines:
- Data as it was recorded
- Data as we know it now
In other words, we would need a column for every time there is a new revision. Using the above Federal Reserve data above makes this more concrete. Skip the code and look at the spreadsheet data underneath it if you’re not familiar with Python.
import pandas as pd
import urllib
url = 'https://raw.githubusercontent.com/leosmigel/...
analyzingalpha/master/2019-10-09-look-ahead-bias/unemployment.csv'
with urllib.request.urlopen(url) as f:
unemployment = pd.read_csv(f, parse_dates=True,
index_col='observation_date')
print(unemployment.head()) 2017-01-24 2017-03-13
observation_date
2012-01-01 0.3 0.3
2012-02-01 0.4 0.4
2012-03-01 0.4 0.5
2012-04-01 -0.3 -0.2
2012-05-01 -0.1 0.0
The ALFRED data provides us with bitemporal data with three columns:
- The observation date
- The initial observation data
- The revised observation data
We would need to add a column for each revision. Again, we always need to know how the data was at recording and how it is today. Providing the correct data to our backtesting software is the first step in preventing look-ahead bias.
Look-Ahead Bias in Backtesting Systems
Look-ahead bias can still creep into our backtests even with the correct data. There are two types of backtesting software:
- Vectorized “for-loop” backtesting systems
- Event-driven backtesting systems
Vectorized Backtesting Systems
A vectorized, for-loop backtester is the most straightforward type of backtesting system. Vectorized systems loop over each trading day and perform a calculation, such as a [moving average/moving-average) on the data set. The danger with vectorized, for-loop backtesters is that they are prone to look-ahead bias due to mistakes with indexing.
For instance, with the Federal Reserve data above, what should your unemployment data value be for 2012-04-01 on 2017-01-24 if you’re an Australian trader? What about 2017-03-13? It’s easy to make a mistake if you’re not careful. This is a logical indexing problem, and event-driven backtesting systems prevent this from happening.
Event-Driven Backtesting Systems
Event-driven systems are much more complex and closely replicate the live trading performance. Without getting too technical, event-driven systems eliminate look-ahead bias at the trading level by using queues and passing messages.
Armed with bias-free data and an event-driven backtesting system, you’re taking the first steps to developing a good backtest.