Attention algorithmic traders and programmers! Are you tired of shelling out big bucks for professional transcription and news services? Look no further than OpenAI Whisper. This state-of-the-art, open-source speech transcription tool will revolutionize how you transcribe audio recordings.
In this tutorial, you’ll learn how to call Whisper’s AI model endpoints in Python and see firsthand how it can accurately transcribe earnings calls. Plus, we’ll show you how to use OpenAI GPT-3 models for summarization and sentiment analysis.
Whether you’re a transcription company, a natural language processing researcher, or a casual programmer, Whisper will save you time and money. Say goodbye to tedious manual transcriptions and hello to a world of efficiency with Whisper.
Interested in following along? Check out the OpenAI Whisper Python Tutorial Jupyter Notebook.
What is OpenAI Whisper?
Listen up! (see what I did there) Whisper is a powerful AI tool that recognizes speech and translates it automatically. With 680k hours of labeled data behind it, Whisper can handle any dataset or domain without needing extra tuning. It was first suggested by Alec Radford and his team at OpenAI in their groundbreaking paper “Robust Speech Recognition via Large-Scale Weak Supervision.” And the best part? OpenAI released it in October 2022 as their first open-source and free AI model.
Whisper Pros and Cons
Are you considering using OpenAI’s Whisper for speech recognition and translation? Before you make a decision, it’s essential to weigh the pros and cons of this cutting-edge tool.
Pros:
- Whisper is free of cost.
- It is open-source, allowing you to see what’s happening behind the scene.
- Whisper supports multiple languages.
- Offers multiple models catering to varying performance and speed requirements.
Cons:
- Whisper is not capable of streaming transcriptions. It only allows offline transcriptions for now.
- Some users express privacy concerns since it is unclear how Whisper stores and processes audio files.
Whisper Price Plans
Whisper models are free. You can use Whisper models in your Python applications without signing up for an OpenAI account.
Getting Started with OpenAI Whisper
Pay attention, folks! Here’s the great thing about Whisper: you don’t need an API key to use it in Python. All you have to do is download the open-whisper library, choose a model, and get transcribing.
But remember, Whisper models are massive and use top-of-the-line deep learning and transformer models. To get the best performance, try running it on a GPU architecture. Don’t have one of those? No worries! Just use Google Colab, a free and convenient cloud-based platform for running large deep-learning models on GPU.
Install Whisper Python Library
Here’s how to install the Python wrapper for Open AI Whisper in just one easy step! Use this pip command.
!pip install -U openai-whisperLoad Whisper Models
Whisper offers five transcription models that vary in accuracy and speed.

The tiny, base, small, and medium models have English-only (ending with .en) and Multilingual versions. The largest model only has a single multilingual version.
The tiny model is the smallest, fastest, but the least accurate. The largest model is the most accurate but can be very slow. Per my experience, the base model is sufficiently accurate for everyday audio transcription tasks.
The whisper module’s load_model() method loads a whisper model in your Python application. You must pass the model name as a parameter to the load_model() method.
import whisper
model = whisper.load_model("base")Transcribe Audios
With Whisper, you can transcribe audio files in just a few lines of code.
The transcribe() method from the model object transcribes audio. The method accepts the path to the audio file as a parameter value.
The following script uses the transcribe() method to transcribe the audio file harvard.wav (which you can download from Kaggle).
The transcribe() method returns a Python dictionary containing transcription text, transcription segments, etc. You can fetch the transcription text using the text key of the dictionary.
# path to download the dataset
#https://www.kaggle.com/datasets/pavanelisetty/sample-audio-files-for-speech-recognition
result = model.transcribe("/content/harvard.wav")
result["text"]Transcribing long audio files can take quite a bit of time. In such cases, you can see transcription progress by passing True as the value for transcribe() method’s verbose attribute.
In the output, you will see transcribed text segments on the fly.
result = model.transcribe("/content/harvard.wav", verbose = True)
print(result["text"])Process Response
The way you process Whisper’s response is subjective. You can fetch the complete text transcription using the text key, as you saw in the previous script, or process individual text segments.
The segments key of the response dictionary returns a list of all transcription segments. Each item in the segments list is a dictionary containing segment information such as segment text, start and end time of the segment in the audio, etc.
result['segments']You can iterate through the segments list and print the text for each segment using the text key.
for i, seg in enumerate(result['segments']):
print(i+1, "- ", seg['text'])Another option is to convert the list of segments into a Pandas DataFrame using the Pandas DataFrame’s from_dict() method.
import pandas as pd
speech = pd.DataFrame.from_dict(result['segments'])
speech.head()Do you know what’s even cooler than transcribing speech with Whisper? Using it to detect the language of the audio! Yup, you read that right. Keep reading to see how it’s done.
Language Detection
For language identification, you first need to load the audio using the load_audio() method from the whisper module. Next, you pad or trim the audio using the pad_or_trim() method, which pads or trims your audio file to the specified duration. The default size is 30 seconds.
audio = whisper.load_audio("/content/harvard.wav")
audio = whisper.pad_or_trim(audio)Whisper models are statistical algorithms that work with numbers. You must convert audio data to numbers before Whisper models can process it. You can use the Log Mel Spectrogram technique for the numerical feature representation of audio signals.
The following code creates a feature representation of your audio file using the log_mel_spectrogram() method and then moves the feature map to the same device as the model.
You can then use the detect_language() method of the model object and pass the feature map to it. In the output, you will see the detection probability for various languages.
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
probs
You can see that the English language (en) has the highest probability of 99.7%, followed by Chinese (zh) and German (de).
Note: The language codes follow ISO-639-1 standard language codes.
You can get the language with the highest probability using the following script.
print(f"Detected language: {max(probs, key=probs.get)}")
In the following sections, you will see examples of leveraging Whisper models in real-world scenarios. You will use OpenAI GPT-3 model in conjunction with Whisper models to perform the following tasks:
- Transcribing Earning Calls with Whisper
- Summarizing Whisper-Transcribed Earnings Calls using GPT3
- Perform Sentiment Analysis on Earning Calls using CPT-3
Transcribing Earnings Calls with OpenAI Whisper
Earnings calls are like an “inside look” into how publicly traded companies are doing financially. These calls can significantly impact the company’s stock price, making them critical for investors and stakeholders.
With Whisper, you can quickly transcribe these calls, so you don’t miss a beat! Plus, you can quickly summarize the call’s content, identify critical information, and even track the company’s financial performance over time. In this section, you’ll see how to use Whisper to transcribe Microsoft’s Q4 earnings call in 2022 – it’s easier than you think!
Download Earnings Calls from YouTube
We will first download Microsoft’s earnings call for Q4 2022 from YouTube. To do so, you can use the Python pytube module.
The following script installs the pytube module.
!pip install pytube -qThe YouTube class from the pytube module allows you to download a YouTube video. You must pass the video link to the YouTube class constructor.
from pytube import YouTube
youtube_video_url = "https://www.youtube.com/watch?v=3haowENzdLo"
youtube_video_content = YouTube(youtube_video_url)The YouTube object returns audio and video streams of various sizes for the video.
for stream in youtube_video_content.streams:
print(stream)
Since we are only interested in the audio streams, we can filter them via the following script.
audio_streams = youtube_video_content.streams.filter(only_audio = True)
for stream in audio_streams:
print(stream)
You have three audio streams with sizes 48kbps, 128kbps, and 160kbps. You can use any of these streams for transcription. I used the 128kbps stream.
audio_stream = audio_streams[1]
print(audio_stream)
Finally, you can download the stream using the download() method.
audio_stream.download("earnings_call_microsoft_q4_2022.mp4")Trim Earnings Calls with FFMPEG
If you open the YouTube video, you will see that the presentation starts at 32:04 seconds and ends at 1:13:59 seconds. The video contains random music followed by a short introduction before 32:04 seconds. The presentation ends at 1:13:59, followed by a question answers session.
I will only transcribe the presentation. You can transcribe the Q&A session as well if you want.
For trimming the earnings call, I will use FFMPEG, a free, open-source command-line tool for cutting audio, video, and multimedia files. It is a cross-platform software that can be used on different operating systems like Windows, macOS, and Linux.
The FFMPEG official website explains the installation process for FFMPEG binaries.
If you are working with Google Colab, like myself, FFMPEG is preinstalled. You can check the FFMPEG version installed on your system using the following script.
!ffmpeg -version
To trim audio using the FFMPEG tool, you need to specify the start time and the duration of the audio to cut. In our case, the start time is 32:04, which converts to 1924 seconds. We want to trim the video to 1:13:59, which converts to 4439 seconds. The total duration of the video to trim will be 4439 – 1924 = 2515.
The following script trims our audio file. Here:
- /content/earnings_call_microsoft_q4_2022.mp4/Microsoft (MSFT) Q4 2022 Earnings Call.mp4 is the path to the input file.
- Earnings_call_microsoft_q4_2022_filtered.mp4 is the name of the output trimmed file.
# presentation starts from 32:04 and ends at 1:13:59
# QA starts from 1:13:59
# https://www.metric-conversions.org/time/minutes-to-seconds.htm
!ffmpeg -ss 1924 -i "/content/earnings_call_microsoft_q4_2022.mp4/Microsoft (MSFT) Q4 2022 Earnings Call.mp4" -t 2515 "earnings_call_microsoft_q4_2022_filtered.mp4"
We are now ready to transcribe our earnings call.
Transcribe Earnings Calls
Transcribing an earnings call via Whispers is similar to transcribing any other audio file. You must load a transcription model and call the transcribe() method by passing the path to the audio file for the earnings call.
import whisper
model = whisper.load_model("base")
result = model.transcribe("/content/earnings_call_microsoft_q4_2022_filtered.mp4")
result["text"]The above output shows that our model successfully transcribes the contents of the earnings call. The above result only shows the first few lines of the transcription. Using Colab, you can click the small squares at the bottom right corner to view the complete transcription.
Summarizing Whisper-Transcribed Earnings Calls with GPT-3
Once you have text transcription of an audio file, you can perform any natural language processing task, e.g., text classification, summarization, topic modeling, etc.
In this section, you will see how to summarize earnings calls using the OpenAI GPT-3 model, the state-of-the-art language model for various NLP tasks.
I have written a detailed tutorial on how you can perform various NLP tasks with OpenAI API in Python. You can refer to that article in the following sections for clarification.
For example, in this section, I will summarize the first 985 characters of the earnings call transcription; you can summarize any number of characters or the complete earnings call if you want, though it will cost a lot more.
The first 985 characters of our earnings call are as follows:
result['text'][:985]
The first step for summarizing the earnings call via OpenAI API is to install the Python wrapper for OpenAI API. You can use the following command to do so.
!pip install openaiNext, import the openai module, assign your API key to the api_key attribute of the openai module, and call the create() method from the Completion endpoint.
You must pass the text you want to summarize to the prompt attribute of the create() method. Append nnTl;dr at the end of the prompt, which tells the GPT-3 model you want to summarize the text. The model in the following example is the text-davinci-003 model, the most advanced GPT-3 model. You can use other models as well if you want.
The max_tokens attribute specifies the number of words in the summary. Roughly 100 tokens equal 75 English words. A smaller token size generates shorter summaries.
By default, the number of tokens in your prompt and the output should not collectively exceed 2000. So if you want to transcribe the whole earnings call, you must divide it into segments where each input segment and output summary should contain less than 2000 tokens.
The following script summarizes a part of the text from the earnings call you transcribed in the previous section.
import os
import openai
api_key = os.getenv('OPENAI_KEY')
openai.api_key = api_key
text = result['text'][:985]
summary = openai.Completion.create(
model="text-davinci-003",
prompt= text + "nnTl;dr",
max_tokens= 200,
temperature=0
)
print(summary['choices'][0]['text'])
In the next section, you will see how to find the sentiments of text segments in the earnings call.
Sentiment Analysis of Earnings Calls with GPT-3
Sentiment analysis of earnings calls is essential for investors as it helps them to understand the overall mood and tone of the company’s management. By analyzing the sentiment, investors can gain insights into the company’s prospects, identify discrepancies between the management’s statements and actual results, and make informed investment decisions. It is a critical tool for gauging a company’s performance, financial health, and potential risks and challenges.
This section will show how to perform sentiment analysis of earnings call transcriptions. You will use the OpenAI GPT3 Davinci model for finding sentiment.
You can find the sentiment of the complete earnings call if the transcription consists of less than 2000 tokens, which is rarely the case. You will have to partition your earnings call into multiple segments and then find the sentiment of the individual segment.
In this section, you will find earnings call sentiments at two levels.
- The sentiment of default Whisper audio segments
- The sentiment of manually segmented Whisper transcriptions
Sentiment Analysis of Default Whisper Speech Segments
As you have seen before, Whisper divides audio transcriptions into segments. You can find the sentiment of each default segment. Let’s see how you can do this.
The following script stores earnings call segments into a Pandas DataFrame and filters the “text” column. Next, for demonstration, we randomly select 20 records from the Pandas dataframe. I didn’t select the first 20 records since they comprise the introduction.
# convert earnings call response to pandas dataframe
earnings_callDF = pd.DataFrame.from_dict(result['segments'])
# filter the text column and remove the remaining
earnings_callDF = earnings_callDF[['text']]
# randomly select 20 segments from the dataframe
earnings_callDF = earnings_callDF.sample(n = 20)
earnings_callDF.head()
You can define a method that accepts text as input and returns the sentiment of the text.
The get_sentiment() method in the following script accepts text as a parameter and returns the sentiment of the text using the create() method from the openai.Completion endpoint.
The prompt, in this case, tells the GPT-3 Davincin model to classify the sentiment of the input text as positive, negative, or neutral. You can modify this prompt to add more sentiments.
The output may contain newline characters, e.g., n, etc., which you can remove using Python regex expressions.
import re
def get_sentiment(text):
prompt_text = """Classify the sentiment of the following earnings calls text as as positive, negative, or neutral.
text: {}
sentiment: """.format(text)
sentiment = openai.Completion.create(
model="text-davinci-003",
prompt = prompt_text,
max_tokens= 15,
temperature=0,
)
# remove special characters e.g n etc, from response
sentiment = re.sub('W+','', sentiment['choices'][0]['text'])
return sentimentLet’s pass some fictional text to the get_sentiment() method and see what sentiments we get.
text = "This year has been financially very profitable for us."
print(get_sentiment(text))
text = "We lost 20% of our worth in the last quarter ."
print(get_sentiment(text))
You can use the Pandas apply() method to find sentiments of all texts in your Pandas dataframe. You can store the resultant sentiments in a new column.
# apply the get_sentiment() method on our earnings_calls dataframe
earnings_callDF['sentiment'] = earnings_callDF['text'].apply(get_sentiment)
earnings_callDF.head()
Let’s plot a bar plot that displays the count for each sentiment type.
import seaborn as sns
sns.set_style("darkgrid")
sns.set(rc={'figure.figsize':(10,7)})
sns.set_context("poster")
print(earnings_callDF['sentiment'].value_counts())
sns.countplot(x='sentiment', data = earnings_callDF)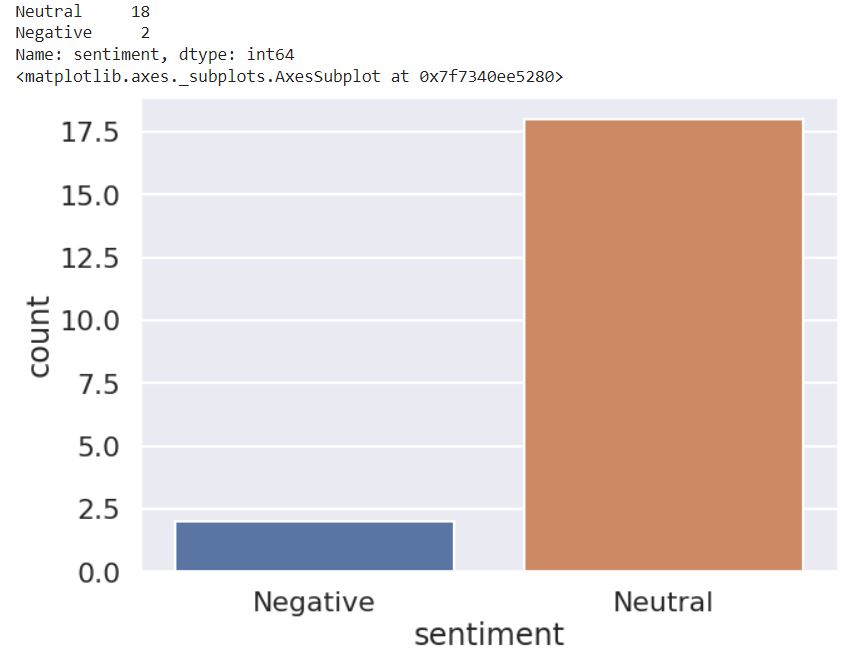
You can see that 18 out of 20 segments in the input dataframe are negative.
Let’s display one of the segments along with its sentiment.
print("text - ",earnings_callDF['text'].iloc[12])
print("sentiment - ",earnings_callDF['sentiment'].iloc[12])You can see that the text segment seems incomplete, and even humans cannot classify it as positive or negative. The same is the case with the Davinci model. It is unable to infer whether the segment is positive or negative. Since we gave the model three choices, it classified the segment as neutral.
for i, seg in enumerate(result['segments'][100:110]):
print(i+1, "- ", seg['text'])Let’s print some random segments from the Whisper transcribed earnings call.
You can see that most of the segments are incomplete. The GPT-3 model will classify most of them with a neutral sentiment.
The above results show that finding the sentiment of default Whisper segments is not a good idea. A better approach is to manually segment transcriptions so that the resultant segments are complete and meaningful.
Sentiment Analysis of Manually Processed Speech Segments from Whisper Transcriptions
In this section, we will manually segment transcriptions using a period as a delimiter and then find the sentiment of each segment. Many advanced segmentation techniques exist that return meaningful segments from the text. For the sake of simplicity, I will use the period as a delimiter.
The following script segments the earnings call transcription using the split method. We then print the first five segments. You can see that the segments now look complete and more meaningful.
segments = result['text'].split(".") # use period as a segment delimiter
segments = [segment + "." for segment in segments]
segments[:5]
The rest of the process is the same as before. You can create a Pandas dataframe containing manual text segments.
earnings_callDF_custom = pd.DataFrame(segments, columns=['text'])
earnings_callDF_custom.head()Next, you can apply the get_setiment() method on your Pandas dataframe to get the sentiment of each text segment in the pandas dataframe.
# randomly select 20 segments from the dataframe
earnings_callDF_custom = earnings_callDF_custom.sample(n = 20)
earnings_callDF_custom['sentiment'] = earnings_callDF_custom['text'].apply(get_sentiment)
earnings_callDF_custom.head()
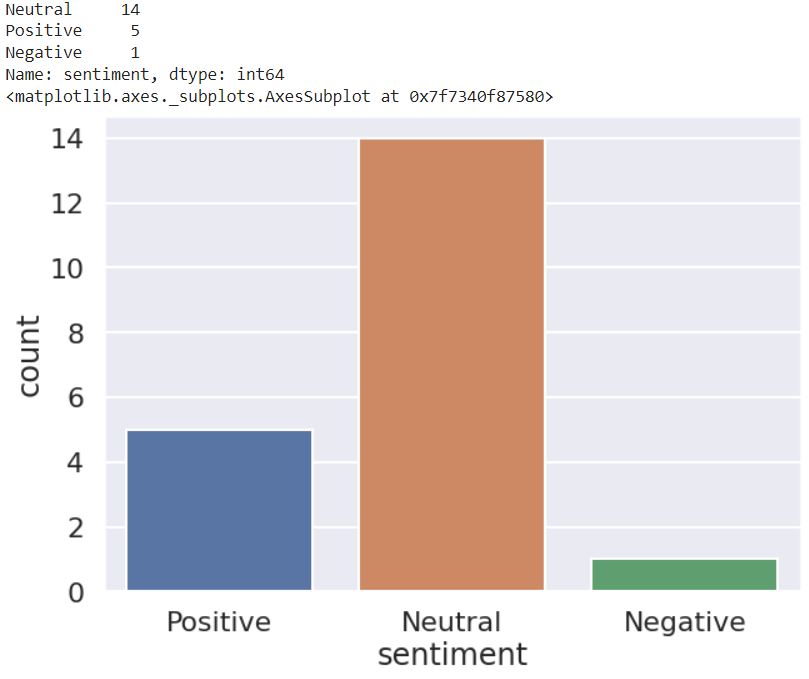
If you plot the sentiment count, you can see that we have positive, negative, and neutral sentiments. Though neutral sentiment still dominates, we also have many positive sentiments since the GPT-3 model has complete information for making a prediction.
print(earnings_callDF_custom['sentiment'].value_counts())
sns.countplot(x='sentiment', data = earnings_callDF_custom)| print(earnings_callDF_custom[‘sentiment’].value_counts()) sns.countplot(x=’sentiment’, data = earnings_callDF_custom) |
Let’s print text segments with positive sentiment.
positive_texts = earnings_callDF_custom[earnings_callDF_custom['sentiment'] == 'Positive']['text'].tolist()
for i, pos in enumerate(positive_texts):
print(i, " - ", pos)
All the above text segments convey positive sentiments.
You can also print segments with negative sentiments.
negative_texts = earnings_callDF_custom[earnings_callDF_custom['sentiment'] == 'Negative']['text'].tolist()
print(negative_texts)
Whisper is an excellent free and open-source option for audio transcription. However, there are other tools in the market, as you will see in the next section.
Whisper Alternatives
Following are some alternatives to OpenAI Whisper:
Frequently Asked Questions
Is OpenAI Whisper Free?
Yes, OpenAI Whisper is free to use. You don’t need to signup with OpenAI or pay anything to use Whisper.
Is OpenAI Whisper Open Source?
Yes, Whisper is open-source. The code for Whisper models is available as a GitHub repository.
How Accurate Is Whisper AI?
OpenAI states that Whisper approaches the human-level robustness and accuracy of English speech recognition. The actual accuracy varies depending on the specific model used. Generally, the larger the model, the more accurate the results, with the tiny model being the least accurate and the large model being the most accurate.
OpenAI reports the accuracy of its models in terms of WER (Word Error Rate), which refers to the number of words in the transcription that differ from the actual words spoken in the input audio. You can find the details of WER for Whisper models in Appendix D of the Research paper that introduces Whisper Models.
Who Owns Whisper AI?
OpenAI, an AI research and development company, owns Whisper AI. Whisper is open-source and free to use under the MIT license.
Is Whisper a General Purpose Speech Recognition Model?
Yes, Whisper is a general-purpose speech recognition model. You can use it to transcribe audio from various domains.
OpenAI Whisper Supported Languages?
Currently, Whisper supports audio-to-text transcriptions for 99 languages. Whisper also supports translating text from these languages into English.
The Bottom Line
Congratulations! You now have the knowledge and tools to transcribe audio files effortlessly and accurately using OpenAI Whisper. This tutorial gave you a step-by-step guide for using Whisper in Python to transcribe earnings calls and even provided insight on summarization and sentiment analysis using GPT-3 models.
You can use this information to customize speech recognition for any industry, including finance. Integrating OpenAI Whisper into your workflow can streamline transcription and save valuable time and resources.
Don’t wait any longer to try this fantastic audio transcription solution – OpenAI Whisper is the perfect choice for anyone seeking fast, precise, and dependable transcription.